在当今科技浪潮之巅,智能驾驶无疑是最引人瞩目、也最具挑战的赛道之一。当我们在讨论不同品牌的自动驾驶能力时,其背后真正的较量,是关于技术架构和实现路径的“路线之争”。这条演进之路,正从传统的“模块化”设计,经历“端到端”的革命,走向“VLA”和“WEWA”的未来探索。
让我们通过一个具体的驾驶场景,看看这些不同的“大脑”会如何思考和行动。
场景设定: 一辆智能驾驶汽车正在以 40 公里/小時的速度行驶在城市道路上,前方不远处有一个人行横道。一个皮球突然从路边滚到人行横道上,旁边还有一个小孩,看起来正欲追逐皮球。
时代一:稳健可靠的“模块化”总成
这套方案如同一个分工明确的工厂流水线,将驾驶任务拆解为感知、预测、规划、控制等独立模块。
- 它是如何工作的?
- 感知模块报告:“识别到前方 30 米处有人行横道、一个球形物体(分类:玩具)、一个儿童(分类:行人)。儿童位于人行道边缘,正在朝向皮球。”
- 预测模块分析:“根据行为模型库,儿童追逐玩具的概率为 95%。预测其将在 0.5 秒内进入车道。”
- 规划模块决策:“当前车速 40 公里/小时,存在碰撞高风险。必须立即执行紧急制动策略,目标是在人行横道前 5 米处完全刹停。”
- 控制模块执行:“接收到刹停指令,计算出所需的制动力度,执行最大刹车指令。”

添加图片注释,不超过 140 字(可选)
- 一句话点评:逻辑清晰,有条不紊,但高度依赖预先设定的规则库,如果遇到一个规则里没有的罕见物体,感知模块可能就会“卡壳”。
- 潜在的挑战:“信息壁垒”与“长尾难题”。这种流水线式的设计,每个模块只负责自己的任务,并将结果“扔”给下一个模块。这导致了“信息损耗”——规划模块无法得知感知模块识别某个物体时的“置信度”有多高;同时,任何一个模块的微小错误都会在流水线中被逐级放大。更重要的是,它难以处理海量的、未曾被明确定义的“长尾场景”(Corner Cases),因为人类工程师无法为所有未知情况编写规则。
(正是为了打破模块间的壁垒,并更好地处理长尾数据,“端到端”革命应运而生。)
时代二:大道至简的“端到端”革命
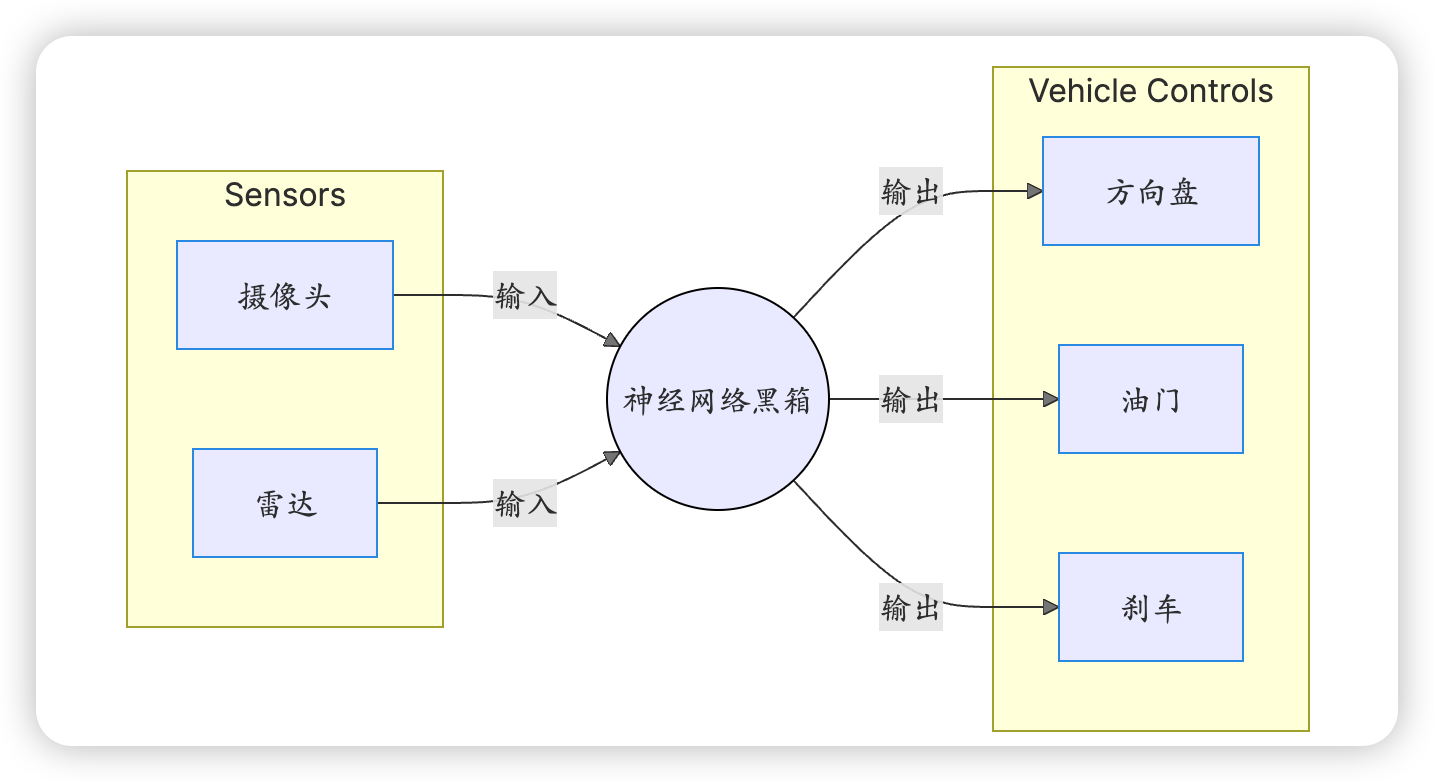
它抛弃了中间繁琐的模块,试图用一个强大的神经网络,直接将“所见”转化为“所行”。
- 它是如何工作的?
- 车辆的摄像头捕捉到“小孩+滚动的皮球”这一画面。这个视觉模式被输入到巨大的神经网络中。
- 在模型的“记忆”里,它曾学习过数百万帧包含此类画面的数据。这些数据无一例外都关联着一个人类驾驶员的动作——“猛踩刹车”。
- 模型不需要进行“预测”或“规划”的逻辑思考,而是基于强大的模式匹配能力,几乎是本能地、直接地输出了一个结果:{转向角度: 0, 油门: 0, 刹车: 100%}。
添加图片注释,不超过 140 字(可选)
- 一句话点评:反应极快,像老司机的直觉,但它是个“黑箱”,你问它为什么刹车,它“说不出来”,只是知道“看到这个就该这么做”。
- 潜在的挑战:“黑箱”困境与“可解释性”缺失。我们无法理解模型内部的决策逻辑,当发生事故时,责任难以界定,调试和改进也如同盲人摸象。更重要的是,它缺乏人类的“常识”和“推理能力”。例如,它可能因为学习过“看到黄色方形要减速”的数据而对着路边黄色的广告牌刹车,却无法理解广告牌和小孩的本质区别。这种缺乏真正理解的能力,限制了其安全性的上限。
(为了让 AI 不仅能“直觉”驾驶,还能像人一样“理解”场景并进行因果推理,“VLA”模型走上了舞台。)
时代三:能说会道的“VLA”模型 (Vision-Language-Action)
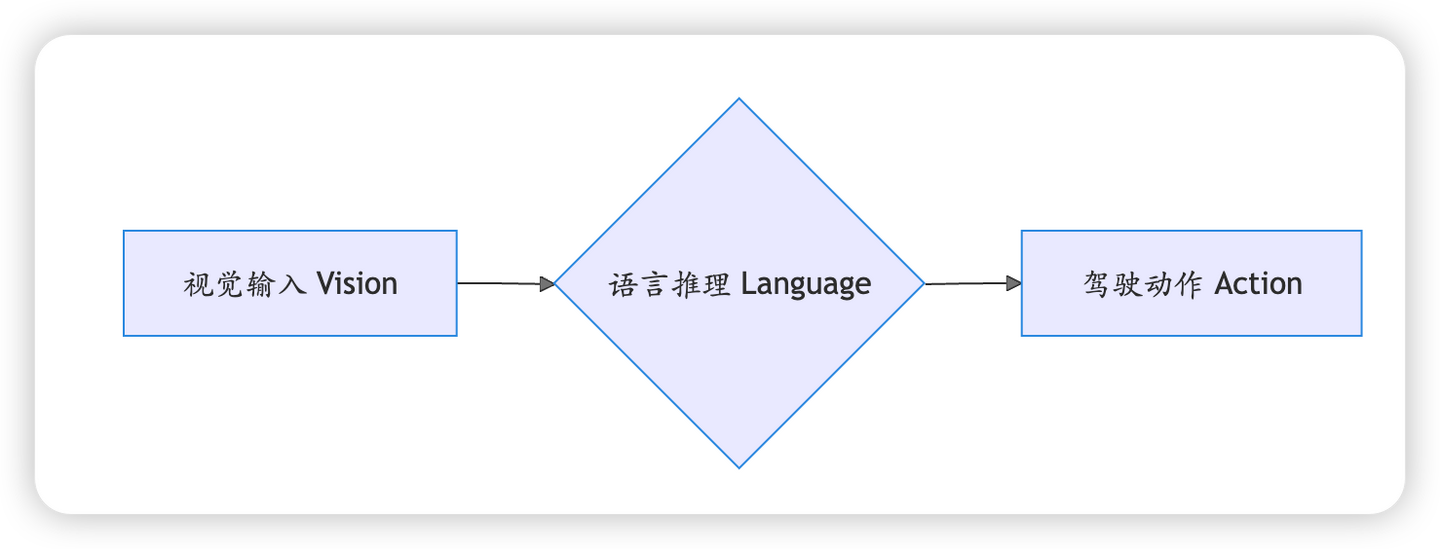
VLA 的目标,就是让车辆学会“解释自己为什么这么做”。它在端到端的基础上,融入了大型语言模型(LLM)的理解和推理能力。
- 它是如何工作的?
- 多模态大模型接收到视觉信息后,不仅识别了物体,还在内部用语言进行“思考”:“我看到一个小孩正在看一个滚到路上的皮球。根据常识,孩子很可能会突然冲到路上追球,这是一个非常危险的信号。因此,最安全的行为是立即全力制动,以避免发生事故。”
- 基于这段内部推理,模型输出了{刹车: 100%}的指令。
- 如果此时车内乘客被急刹吓到,问道:“刚才为什么突然刹车?”系统可以立刻通过语音回答上述那段加粗的“内心独白”。
添加图片注释,不超过 140 字(可选)
- 一句话点评:它不仅会开车,还成了你的“驾驶教练”,能和你沟通决策原因,极大增强了信任感,但也可能因为语言模型的“幻觉”而做出错误判断或解释。
- 潜在的挑战:“语言幻觉”与“效率瓶颈”。将语言作为推理的核心,引入了新的不确定性。模型可能会“脑补”出不存在的事实(例如,“小孩的妈妈在叫他”),并基于此做出错误决策。同时,将视觉信息先“翻译”成语言再决策,可能比端到端的直接映射更慢、更耗算力。最关键的是,人类驾驶时的许多瞬间决策并非基于清晰的语言逻辑,而是一种对物理世界的潜意识和直觉性预判。
(为了超越语言描述,直接构建对物理世界的深刻理解和预测能力,更为终极的“WEWA”架构成为了新的探索方向。)
时代四:终局之战的雏形“WEWA”架构 (World Engine, World Action)
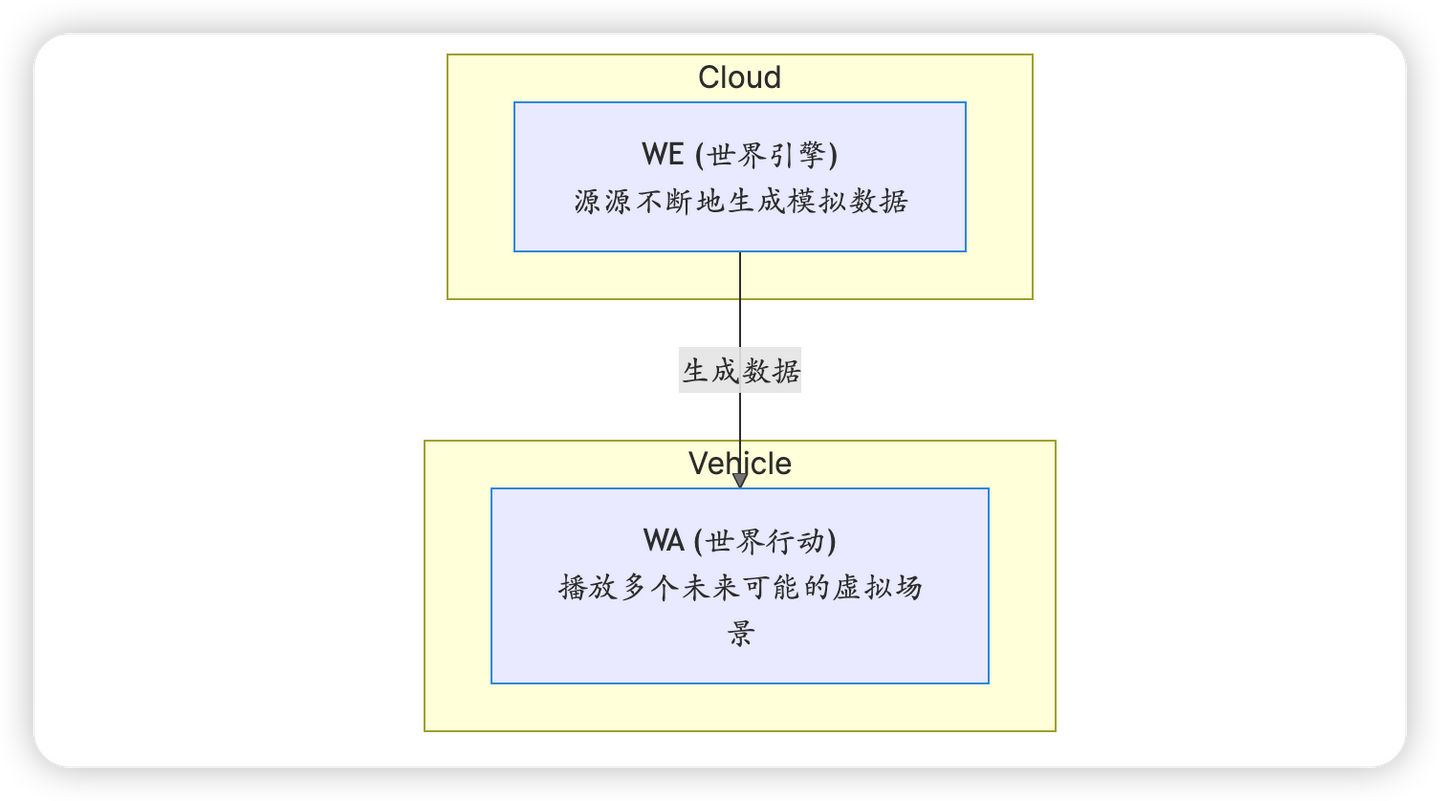
WEWA 架构认为,真正的智能不应依赖语言这个“拐杖”,而应建立对物理世界深刻的理解和预判能力,即构建一个“世界模型”。
- 它是如何工作的?
- 车端的 WA(世界行动)模型看到场景后,它的大脑里没有语言,而是瞬间在内部虚拟世界中进行了多轮“推演”或“想象”:
- 推演 A:“如果我保持速度,未来 1.5 秒后,我的车头会在这里,小孩会在这里,结果是碰撞。”
- 推演 B:“如果我中度刹车,未来 2 秒后,我的车头会在这里,小孩会在这里,结果是可能碰撞。”
- 推演 C:“如果我全力刹车,未来 2.5 秒后,我的车在这里停下,小孩在这里拿到球,结果是安全。”
- 模型对比了所有推演结果,选择了通往“安全”未来的那条世界线,并立刻执行了全力刹车的动作。
- 与此同时,这个真实的棘手场景数据会被传到云端的 WE(世界引擎),后者会以此为蓝本,生成成千上万个相似但不同的虚拟场景(比如换成老人、雨天路滑等),对车端模型进行持续的强化训练。
添加图片注释,不超过 140 字(可选)
- 一句话点评:它像一个拥有“最强大脑”的棋手,能在脑中预判未来多种可能性并选择最优解,这是通往完全自动驾驶最令人兴奋、也是技术上最艰难的路径。
- 潜在的挑战:“理想与现实”的巨大鸿沟。构建一个精准、实时的“世界模型”是人工智能领域最艰巨的挑战之一。如何保证模型推演的物理规律与现实世界完全一致?其对人类行为的推演是否足够准确?这套架构对计算能力的要求达到了前所未有的高度,目前更多是一个宏伟的理论框架,其工程化落地的道路漫长且充满未知。
总结与对比
从模块化的“流水线工人”,到端到端的“直觉司机”,再到 VLA 的“沟通教练”,最终到 WEWA 的“未来预言家”,智能驾驶的技术路线正以惊人的速度进化。为了更清晰地理解它们的区别,请看下表:
| 技术路线 | 核心逻辑 | 好比一个… | 关键优势 | 核心挑战 | 场景处理方式 |
|---|---|---|---|---|---|
| 模块化 | 分工协作,规则驱动 | 工厂流水线 | 逻辑清晰,易于调试 | 信息壁垒、难以应对未知长尾场景 | 按部就班地分析和决策 |
| 端到端 | 直接映射,数据驱动 | 直觉反应的新手司机 | 架构简单,反应快 | “黑箱”不可解释、缺乏常识推理 | 看到模式,直接反应 |
| VLA | 融合语言,推理决策 | 能言善道的驾驶教练 | 可解释,懂常识 | 语言“幻觉”风险、决策效率瓶颈 | 边思考边解释边行动 |
| WEWA | 模拟世界,预判未来 | 预判棋局的顶尖棋手 | 突破数据瓶颈,直达物理本质 | 技术难度极高、算力要求巨大、模型尚不成熟 | 在脑中预演未来,选最优解 |
这场技术路线的“战争”没有绝对的对错,更像是一场持续的“进化”。后一种技术的诞生,正是为了解决前一种技术所暴露出的核心缺陷。模块化受困于长尾问题,催生了数据驱动的端到端;端到端的“黑箱”特性催生了可解释的 VLA;而 VLA 对语言媒介的依赖,又推动人们去追求更本质、更接近物理世界运行方式的 WEWA。不同的厂商根据自身的技术积累、资源禀赋和对未来的判断,选择了不同的道路。但无论路径如何,它们的目标都指向同一个终点:一个比人类驾驶更安全、更高效、更可靠的智能出行未来。而我们,正处在这场伟大变革的最前沿。