背景
最近遇到一个下载的需求,由于 url 参数太长(常用的下载方法 a 标签或者 location.href 的方法都是 get 请求,get 请求参数长度有限制),无法下载,考虑了好几种方案,最终还是觉得通过 ajax 的 POST 方法进行下载,比较容易实现,下面记录实现过程以及遇到的问题。
但是由于 AJAX 并不会唤起浏览器的下载窗口,AJAX设计的初衷就是用来实现异步刷新的,用以改善原始的 form 表单提交刷新页面的问题,那么如何来解决呢?
POST 方法下载实现原理
通过 fetch 请求获取文件,然后利用 Blob 对象来接收处理,在接收到后端返回的文件后,把其转化一下,放入a标签的href中,并触发下载行为。
实现的代码如下:
fetch(url, {
method: 'POST',
body: JSON.stringify(params),
header: {
'Content-Type': 'application/json;charset=UTF-8'
}
}).then(function(response) {
return response.blob();
}).then(function(blob) {
const link = document.createElement('a')
link.style.display = 'none'
link.href = URL.createObjectURL(blob)
document.body.appendChild(link)
link.click()
// 释放的 URL 对象以及移除 a 标签
URL.revokeObjectURL(link.href)
document.body.removeChild(link)
});这里需要注意的是要记得要调用 response 的 blob 方法,这样才会返回一个 blob,如果你没用过 blob 的话,可能你以前只知道 json 和 text,其实 response 的 body 还可以转化为 arrayBuffer 和 formData。
具体 Response 可以见 MDN
如何拿到文件名
可以下载文件了只是第一步,但是你会发现还有一个问题,下载下来的文件名是你看不懂的名字,类似这样:
我这边的方案是把文件名放在 response 的 headers 里,放在 content-disposition 字段里,有个 fileName 字段,用来存放文件名。
我感觉在下载文件的时候 content-disposition 字段对于他们后端来说感觉是都会加的,因为最开始我用 get 下载的时候就已经有这个字段了,如果你们后端没有设置这个 header ,可以设置一下,当然也可以设置到其他字段里。

一个小插曲
当我把 fetch 后的 res 打印出来看 Response 的时候,发现 headers 里是空对象,如下:
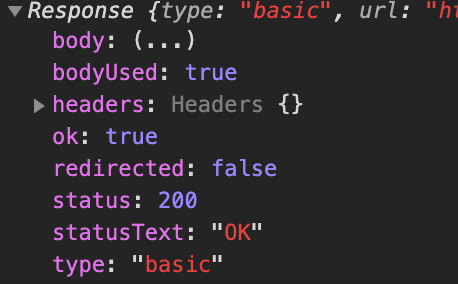
然后我再通过 res.headers 直接去拿 headers,发现还是一个 Headers 的空对象。

我还以为 headers 里面没有东西,但是当我直接通过 res.headers.get('content-disposition') 去拿的时候,竟然拿到了,数据像这样:
attachment;fileName=%E7%9B%B4%E6%92%AD%E6%97%B6%E9%95%BF%E4%B8%BB%E6%92%AD%E6%98%8E%E7%BB%86.xls然后你就可以通过多种方式将文件名给提取出来,我这里采用的是通过 split方法来提取的。
res.headers.get('content-disposition').split(';')[1].split('=')[1]最终的实现
准备工作都做好了,然后就写出了这样的代码:
fetch(url, {
method: 'POST',
body: JSON.stringify(params),
headers: {
'Content-Type': 'application/json;charset=UTF-8'
}
}).then(function(response) {
const filename = res.headers.get('content-disposition').split(';')[1].split('=')[1]
return {
filename,
blob: response.blob()
}
}).then(function(obj) {
const link = document.createElement('a')
link.style.display = 'none'
// a 标签的 download 属性就是下载下来的文件名
link.download = obj.filename
link.href = URL.createObjectURL(obj.blob)
document.body.appendChild(link)
link.click()
// 释放的 URL 对象以及移除 a 标签
URL.revokeObjectURL(link.href)
document.body.removeChild(link)
});本以为就可以了,但是下载下来打开 excel 发现内容是 Promise,然后才发现原来 response.blob() 返回的是一个 promise。
所以改进的实现方案如下:
fetch(url, {
method: 'POST',
body: JSON.stringify(params),
headers: {
'Content-Type': 'application/json;charset=UTF-8'
}
}).then(function(response) {
const filename = res.headers.get('content-disposition').split(';')[1].split('=')[1]
response.blob().then(blob => {
const link = document.createElement('a')
link.style.display = 'none'
// a 标签的 download 属性就是下载下来的文件名
link.download = filename
link.href = URL.createObjectURL(blob)
document.body.appendChild(link)
link.click()
// 释放的 URL 对象以及移除 a 标签
URL.revokeObjectURL(link.href)
document.body.removeChild(link)
})
})不过这种 then 里面又套了 then ,看着有点不好看,所以用 async/await 重新写了一版:
async function postDownload(url, params) {
const request = {
body: JSON.stringify(params),
method: 'POST',
headers: {
'Content-Type': 'application/json;charset=UTF-8'
}
}
const response = await fetch(url, request)
const filename = response.headers.get('content-disposition').split(';')[1].split('=')[1]
const blob = await response.blob()
const link = document.createElement('a')
link.download = decodeURIComponent(filename)
link.style.display = 'none'
link.href = URL.createObjectURL(blob)
document.body.appendChild(link)
link.click()
URL.revokeObjectURL(link.href)
document.body.removeChild(link)j
}这个函数里没有写任何的错误处理,那也不是这篇文章要讲的,不过自己在实现的时候应该加上 try/catch,不然如果有问题,不报错还是很难受的。
